How today’s open data ecosystem companies are bringing the Big Data promise to life
Today’s companies are collecting massive amounts of data to better understand their customers and to make better, more informed business decisions. Frequently, all of this data resides across dozens, sometimes thousands of different sources and in multiple formats, both structured and unstructured. Connecting all of this data and making sense of it is a massive and highly complicated task, but it’s essential. To be successful, companies have to be able to connect the dots across varied data sources and data types. Only then can they realize insights and take meaningful action.
Over the past decade, a series of technologies have come on the scene promising to solve this problem. Led by the Hadoop movement, it first began in the mid-2000s when products and companies started sprouting up, creating an open data ecosystem. This movement towards composable technologies (oftentimes open source, but not necessarily) that integrate with APIs and run on commoditized hardware challenged the status quo of monolithic, interdependent architecture in a big way. By adopting an open, distributed approach on commoditized hardware, these companies challenged the traditional setup of storing and processing data in proprietary, centralized data warehouses. But ultimately, these solutions under-achieved their grandiose promise because they became unwieldy, difficult to manage and economically unscalable.
More recently, we’ve witnessed the revival of the open data ecosystem. Due to the rise of the cloud, a proliferation of open-source data formats and the arrival of vendors solving for earlier pain points, we’ve seen a new breed of open data ecosystem companies emerge and grow in popularity. These new solutions are able to capture the full scope of data that resides within a company, enabling teams to leverage the data to its full advantage.
At Sapphire Ventures, we’ve been investing in a range of enterprise technology companies spanning data, analytics, AI, open source, DevOps, security and more for more than a decade. Having met with hundreds of companies across these industries over the years, we’d like to think we know these areas well. And it’s our belief that open data ecosystem companies are now perfectly in the right place at the right time.
Big Data and the Birth of the Open Data Ecosystem
For decades, companies relied on traditional databases or warehouses, a mostly proprietary, centralized repository where structured data was stored and processed. The traditional data warehouse system required buying pricey on-premises hardware, maintaining structured data in proprietary formats and relying on a centralized data and IT department to deliver analysis.
This system — a or traditional data warehouse — worked while enterprises collected a amount of structured data. But in the mid-2000s, companies like Google ran into challenges with this model. As pioneers in the internet economy, they had to process more raw data than anyone had before, a meaningful amount of which in non-relational format. Google is just one example of a large corporation that needed a place to centrally process structured data (e.g., relational tables), semi-structured data (e.g., logs) and unstructured data (e.g. videos and photos).
At the time, there was no supercomputer big enough for this task. So to keep up, Google wired an ever-expanding number of computers together into a fleet. Eventually, this computing infrastructure grew so big that hardware failures became inevitable, and each programmer had to figure out how to handle them individually. To address these challenges, MapReduce, which could process parallely and generate huge data sets over large clusters of commoditized hardware, was born. As The New Yorker put it, they created “a tool that any programmer at Google could use to wield the machines in its data centers as if they were a single, planet-size computer.” One computation could process terabytes of data across thousands of machines, and coders across the company could use the software to draw insights from Google’s large cache of data. It was such a sight to see that Jeffery Dean and Sanjay Ghemawat publicized their efforts in a titled MapReduce: Simplified Data Processing on Large Clusters .
This famous paper kicked off what we’ll call the first-generation of the open data ecosystem and its first incarnation, Apache Hadoop. Hadoop came to be when the paper caught the attention of two engineers who were working on an open-source web search engine. The duo was so inspired by MapReduce that they then built a free tool, which they released in 2006. The tool is known as Apache Hadoop, which evolved into a collection of open source projects, which served a significant role in bringing open source from academia to the mainstream. The open-source framework allowed anyone to process massive datasets distributed across computer clusters, making it a hugely attractive option for enterprises, which were collecting more data by the day.
Now able to collect and analyze huge amounts of raw data, companies turned to cheaper storage in data lakes, which are large pools of structured, semi-structured and unstructured data. Venture-backed companies like Cloudera, Hortonworks and MapR emerged to make Hadoop more accessible to enterprises, which resulted in many of the world’s largest companies adopting Hadoop. Taken together, Hadoop-based data lakes created the first iteration of the open data ecosystem, bringing to life the real promise of Big Data.
A False Start: Why Hadoop Under-Achieved
Despite its scalability and flexibility at the time, the first generation of the open data ecosystem didn’t achieve the grandiose goals it had laid out. To keep it simple, here are three reasons why Hadoop and the first generation ecosystem fell short:
1. Hadoop was too complex
Hadoop’s philosophy was to integrate as many technologies as possible, trading flexibility, breadth of functionality, and interoperability for simplicity and cost effectiveness. But ultimately, Hadoop was too complex and notoriously difficult for end users to understand and operate. It also required a heavy, IT-centric implementation (needing a large amount of nodes to be effective), so it wasn’t lightweight enough for end users to download for a specific case. Another key challenge for Hadoop was that it was being used for too many things beyond its original intent (ex. interactive analytics wasn’t well supported). Newly formed big data teams measured their success by volume of data stored, not utilized. Adding to all this was that related VC-backed startups like Cloudera and Hortonworks each tried to address everything on the data stack, dragging the open source project in different directions.
2. Difficult to make sense of the data
In a traditional data warehouse, companies carefully modeled their data, defining where information was stored, which was valuable in how it all connected. The process was time-consuming and inefficient (oftentimes taking months and hampered efficiency), but it put structure to data. Hadoop opened up the possibility of indiscriminately dumping data into HDFS and worrying about schema, consumption and management later. With Hadoop, companies could haphazardly dump data into a data lake. Companies would race to collect more and more data, but they weren’t considering architecture design around access, analytics or sustainability. It became difficult for companies to know what was in their data lake and where it came from. And they certainly weren’t able to extract value from it. With tools that could address this problem yet to emerge, businesses collected tons of data, but lacked confidence in consumption. In the end, data lakes turned into data swamps.
3. The economics didn’t work
A few years after Hadoop came on the scene, cloud computing took off in a big way. The cloud made it easier for companies to store data inexpensively on , and , and use services for data governance and management. Meanwhile, Hadoop was still being used for primarily on-prem use cases, and had to be sold and upgraded regularly by centralized IT teams. Expanding capacity meant buying more hardware, requiring up-front investments and months of planning and deployment. The economics became untenable in the age of the cloud.
After all was said and done, the draw of the first generation open data ecosystem became its downfall: Freedom became a free-for-all.
The Open Data Ecosystem Reimagined: You Can Have Your Cake and Eat it Too
Although Hadoop underachieved its promise, the open data ecosystem movement it started (as well as a number of related open source projects such as Apache Spark) is alive and enduring. Its ethos is defined by the following principles:
- Openness: A shift toward open technologies and data standards, as well as interoperability, instead of being locked in with a single proprietary vendor.
- Modularity: A move toward a disaggregated software stack rather than monolithic architecture.
- Diversity: A reliance on a variety of dedicated tools for different use cases, with diverse vendors that compete to drive value for customers.
Along with these principles that are driving an ever-evolving set of open data technologies, a number of key forces have driven the resurgence of the open data ecosystem. With more predictable performance and elasticity in the cloud, query acceleration tech and open source formats that avoid data copies, and better oversight of data contents through associated tech like data governance, you can now have your cake (storing massive amounts of data in open formats elastically) and eat it too (run associated business analytics + AI/ML workloads directly).
At a higher level, for CIOs and CDOs, if data technologies evolve as they inevitably do, going with a data stack with open standards and open source technologies makes your approach to data that much more future proof. Broadly, we think there are four main trends that make today’s Open Data Ecosystem easier to adopt.
1. The rise of the cloud data lake
Thanks to services like Amazon S3, Azure Data Lake Storage (ADLS) and Google Cloud Storage (GCS), companies can house structured and unstructured data at scale in cloud-native data lakes. This eliminates the need for expensive, monolithic hardware and enables organizations to scale data volume without associated management overhead. In addition, the storage costs in the cloud continue to drop. As a result, these storage services have become the default landing zones in the cloud, and are often considered the systems of record. Cloud, with its scale and diversity, inherently encourages disaggregation into best of breed, nimble services. Cloud data warehouses, such as Snowflake, AWS Redshift, and Google BigQuery, while not inherently open, have also tremendously helped bring data to the cloud.
2. Adoption of open-source data formats
More companies are adopting open data formats, such as Apache Parquet (columnar data storage), Apache Arrow (memory format for analytics, artificial intelligence and machine learning) and Apache Iceberg (table format/transaction layer). This makes data more compatible across various programming languages and implementations-including tools that don’t exist yet-rather than depending on a specific tool or vendor, with all the main cloud data lakes supporting these open data formats interoperably.
3. Emergence of cloud-based vendors to support the open data ecosystem
A diverse set of vendors are solving the problems that once plagued Hadoop and the first-generation open data ecosystem, helping make cloud data lakes more manageable. Whereas Hadoop system management was overly complex for users, today’s offer to handle this piece for customers, who can then focus on core business features. Whereas first gen systems still required large capital outlays for on-prem compute and storage, Cloud eliminates the need for expensive hardware to house data lakes, and instead enables resource-based pricing so companies pay based on how much they use the technology. Moreover, tools have popped up that help users manage every aspect of their cloud data lakes:
- Running SQL queries directly in a cloud data lake (Dremio*, Trino/Presto)
- Ingesting data and writing it into open formats (Segment**, Matillion*)
- Streaming in data (Confluent, Materialize)
- Transforming data (Looker**, dbt from Fishtown Analytics)
- Improving observability and quality (Great Expectations, BigEye, Anomalo, Monte Carlo, Lightup)
- Establishing a governance framework (Privacera*, Alation*)
- Syncing data to operational systems (Hightouch, Census, Grouparoo)
- Handling orchestration (Airflow, Prefect, Dagster)
- Providing a flexible and powerful consumption layer for end users (ThoughtSpot*, Looker**)
4. Meet the end user at the right abstraction level
At the end user level, new developments in the open data ecosystem allow data analysts, scientists and business users to do their work at the abstraction level they like. These data users have little interest in what happens underneath the hood and aren’t too concerned about the associated work such as manual schema changes, resource provisioning, database management and so on required in the first-gen open data ecosystem. Conversely, many vertically integrated tools are at a too high of a level when it comes to abstraction. Many of the “user-friendly,” GUI-focused tools from the prior era don’t provide enough flexibility and depth when the end user wants to go one layer deeper.
While the landscape is still rapidly evolving, tools today are designed with abstraction in mind and help the open data ecosystem meet end users exactly where they are in their needs.
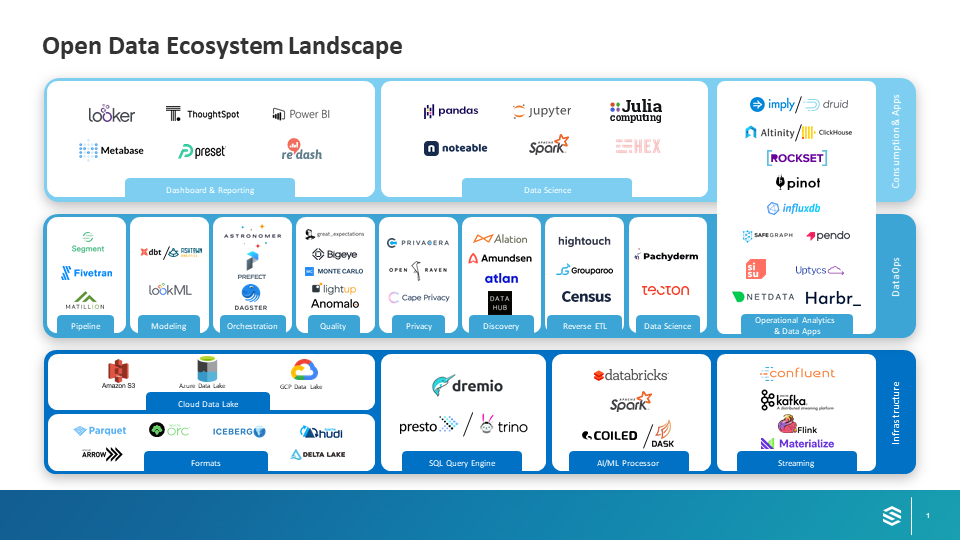
Why We’re Bullish on the Modern Open Data Ecosystem
Just as the ascent of cloud has enabled the new open data ecosystem to flourish, it has also fueled the rise of proprietary cloud data warehouses such as Snowflake (a Sapphire investment made at IPO), which has taken an outsized share as businesses move initial subset(s) of data onto the cloud. Some have argued that Snowflake’s approach, a single cloud data warehouse encompassing every workload, is the only path forward.
At Sapphire, we believe that the cloud data warehouse and cloud data lake will coexist, and data pipelines will often move data around and between the two. As with nearly all things in technology, there’s no single panacea and the real world answer is far more complicated. Nevertheless, over time, just as application development has been shifting from monolithic architectures to microservices-based architectures, we’ll likely see data analytics workloads gradually shift from proprietary data warehouses to open data architectures. That’s why we’ve made bets on companies in the open data ecosystem like Dremio, Privacera, Alation, ThoughtSpot, Segment and Looker.
We’re excited about the modern-day open data ecosystem because it comes with numerous benefits for customers:
- Cost-effectiveness: Cloud data lakes offer the least expensive way to store data today. There is no need to spend time or resources transforming data in order to store or analyze it.
- Scalability: Companies can easily scale their use of the technology, benefitting from the separation of compute and storage
- Choice: Customers aren’t locked in with a single vendor who can set prices and terms. They can take advantage of the best-in-class or highest-value options for specific use cases. Most tools are open-source or SaaS and thus easy to connect and operate.
- Democratization: Anyone can access a company’s data through their preferred framework, without having to use a specific tool or format. That means data analysts, data scientists, application developers and others can efficiently make the most of the data.
- Flexibility: Customers can use their choice of processing engines (Spark, Dask, Dremio, etc.) and store data in any format they want. This is critical for enterprises that have dated, on-premises storage systems that are difficult and costly to move entirely to the cloud.
Going forward, we believe companies will turn to both cloud data warehouses and cloud data lakes to serve different needs and derive value from their data for a long time to come. This time, the open data ecosystem isn’t going anywhere.
- Current Sapphire investments
- **Exited Sapphire investments
Thanks to Abe Gong, Balaji Ganesan, Casey Aylward, Colin Zima, Justin Borgman, Justin Gage, Kevin Xu, Tomer Shiran, Tristan Handy, Seann Gardiner, Shomik Ghosh, Slater Stich, Victor Chang and Viral Shah for your feedback. And shout out to my Sapphire colleagues Anders Ranum, David Hartwig, Jai Das and Nino Marakovic for reading drafts of this.
Source: medium