We launched Dagster because there is a tooling and engineering crisis in the world of data. There is a dramatic mismatch between the complexity and criticality of data and the tools and processes that exist to support it.
Nearly all software development in data boils down to a single activity: building graphs of computations that consume and produce data assets such as tables, files, and trained models. Existing tools that modelled dependency graphs didn’t view this process holistically restricting themselves with deployment and operations. A prime example: today’s most commonly used workflow engine is Airflow, and it has a narrow focus-scheduling, ordering, and monitoring deployed computations.
Dagster isn’t a response to Airflow. It is the result of a first-principles analysis of the state of engineering in data and the tools and systems needed to move it forward. However, since one of Dagster’s capabilities is scheduling and ordering computations in production, we are inevitably evaluated against Airflow and its peer systems. The below comparative analysis of Airflow and Dagster is, by far, our most requested piece of content.
We’ll compare these two systems by looking at how they handle each of the stages of the data life cycle.
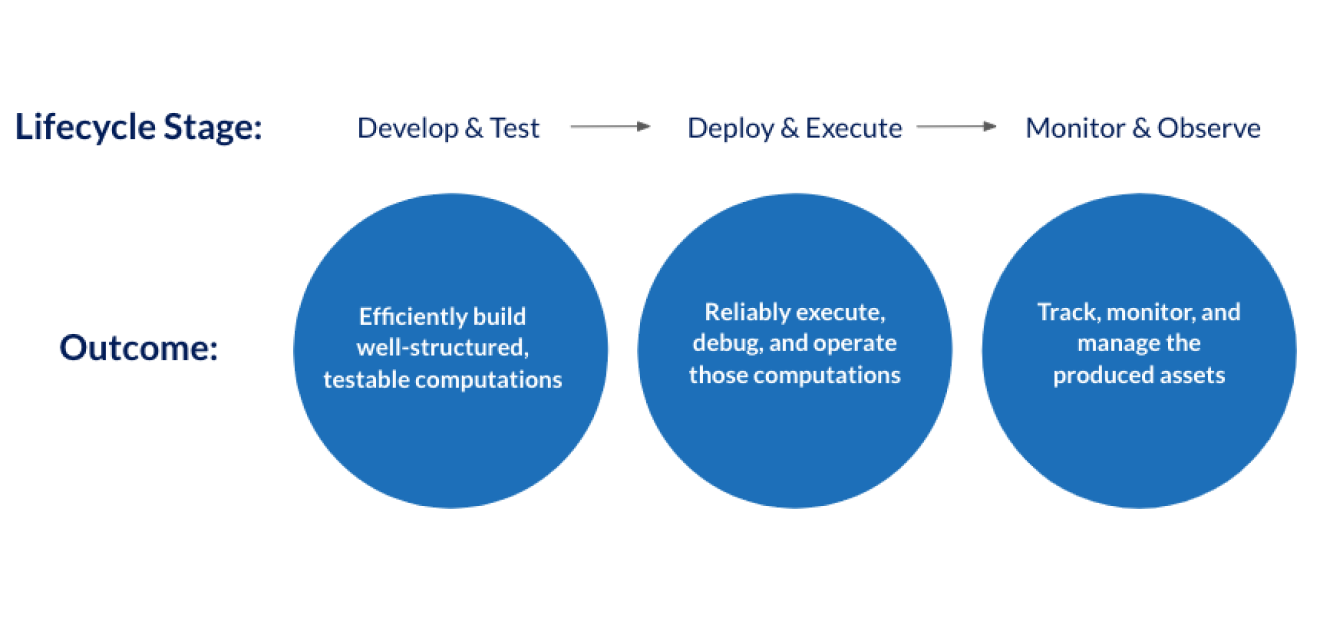
Dagster is built to address each of these stages of the life cycle, delivering:
- A vastly improved development and testing experience for building data applications. Practitioners are more productive and errors are caught earlier, resulting in happier practitioners and higher quality systems.
- An orchestration environment that grows with you, all the way from “single-player-mode” on your laptop to an enterprise-grade, multi-tenant platform.
- A consumer-grade operations, monitoring and observability tool, designed for self-service by a wide range of users.
Develop and Test
Our belief: Data practitioners deserve a complete engineering life cycle with fast development cycles and end-to-end testing. The orchestrator should feel like a productivity tool.
What we hear from Airflow Users:
- “I cannot develop my DAGs locally.”
- “It’s hard to test my DAGs.”
- “I detect way too many errors in staging and production.”
Data practitioners face much slower development and test cycles than their peers in other software engineering disciplines.
If the orchestrator is not intentionally designed for fast development and testing, the graphs modelled in the orchestrator will not be either. Detecting errors earlier and speeding up feedback loops is a massive opportunity. As Erik Bernhardsson puts it: “ getting iteration speeds down by an order of magnitude has dramatic impacts on getting things done.”
Functional Data Processing
Airflow Approach
Airflow’s core abstraction is the DAG (directed, acyclic graph), a collection of tasks connected via execution dependencies. Airflow deliberately knows nothing beyond the names of tasks, which tasks depend on each other, and the raw logs they produce. The Airflow documentation is clear on this point:
“ The important thing is that the DAG isn’t concerned with what its constituent tasks do; its job is to make sure that whatever they do happens at the right time, or in the right order, or with the right handling of any unexpected issues.” link
Airflow does have some support for data dependencies in the form of XCom and TaskFlow, an API introduced in Airflow 2. But it was not designed with them in mind and, in fact, actively discourages data dependencies. From Airflow’s documentation:
“ This is a subtle but very important point: in general, if two operators need to share information, like a filename or small amount of data, you should consider combining them into a single operator. If it absolutely can’t be avoided, Airflow does have a feature for operator cross-communication called XCom…” link
Dagster Approach
Dagster pipelines are graphs of metadata-rich, parameterizable functions — called solids — connected via gradually typed data dependencies. To define a pipeline, the user writes vanilla python functions that define computations and graph structure:
from dagster import pipeline, solid
@solid
def return_one() -> int:
return 1
@solid
def add(x: int, y: int) -> int
return x + y
@pipeline
def add_two():
# builds the dep graph
add(return_one(), return_one())
Like Airflow, we believe that the implementation of a particular graph node can do anything you can do in Python. However, we believe they should formally declare their inputs and outputs, provide typing guarantees for those inputs and outputs, declare their required configuration, and so on. This is a best-of-both-worlds approach that allows for the same flexibility while offering dramatically better tooling support and a familiar API: functions.
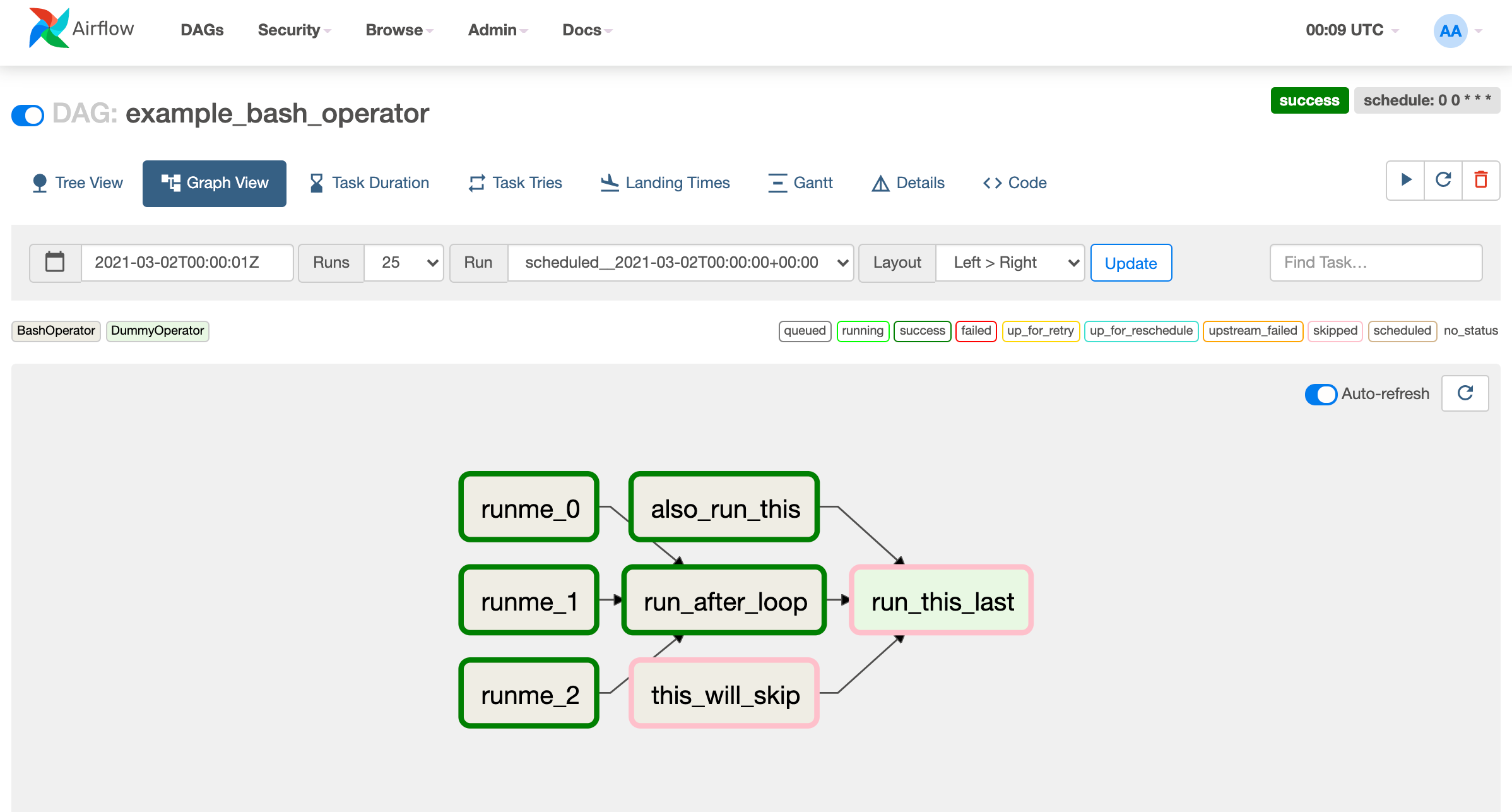
The net result is starkly evident in UI. When viewing a task in the Airflow UI, the viewer’s only information is the task’s name and the task it depends on.
Contrast to Dagster, where beautiful tooling displays descriptions, inputs, outputs, required resources, and other metadata.
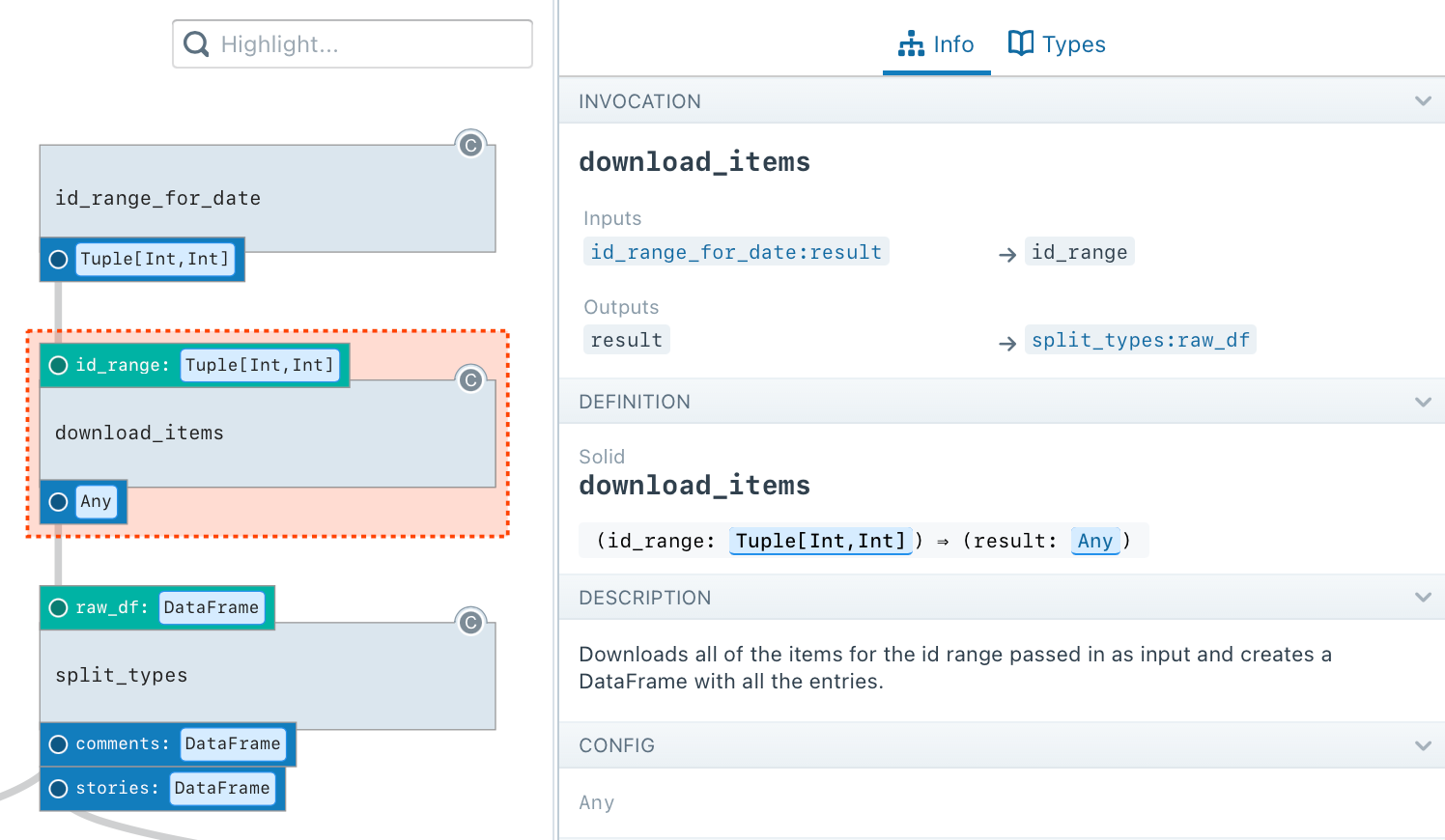
Dagster’s functional data processing confers many advantages beyond self-description, ergonomic APIs, and a richer metadata-driven UI:
- Testability: Functions that model inputs and outputs lets users parameterize execution and directly check results. Testing Airflow DAGs and tasks require setting external state, parameterless execution, and then external state inspection.
- Subset Execution: Executing arbitrary subsets of graphs for testing or operational purposes is straightforward in Dagster since each node can describe its required inputs and configuration. By contrast, Airflow provides no API for DAG subset execution.
- Data Dependencies: Without data dependencies, an Airflow practitioner has to specify dependencies twice: First explicitly at the execution layer by constructing the DAG; then implicitly by manually writing code that fetches the results of upstream computations. Dagster’s data dependencies eliminate an entire class of errors: mismatches between execution dependencies and implicit data dependencies in code.
- Built-in Marshaling: Data processing needs to scale across processes, which requires marshaling the output of one node into the input of another. Dagster provides built-in components and a user-pluggable API for marshalling data between file systems, objects stores, data warehouses, and other storage systems.
- Typing: Dagster inputs and outputs are gradually and flexibly typed. Users can annotate inputs and outputs with Python types and display this in tooling. They can also do deeper data quality checks, schema validation, and enforce other guarantees.
Separation of I/O and Compute
Airflow Approach
Airflow DAGs typically consist of operators such as the SparkSubmitOperator, the KubernetesPodOperator, or the PostgresOperator. Note that these all refer to the specific, deployed infrastructure technologies.
Successful execution requires fully deploying the user-defined infrastructure, whether in development, a CI/CD pipeline, or production. Infrastructure coupling is a key reason why Airflow DAGs resist execution in multiple environments, which prevents a fast, flexible development and test workflow.
Dagster Approach
Dagster’s API enables a separation of concerns between compute and I/O, a necessary condition for testable data applications with fast developer feedback. Separation of compute and I/O at the graph level requires explicit support from the orchestration framework.
@solid
def filter_over_50(people: DataFrame) -> DataFrame:
return people.filter(people['age'] > 50)
In the above example, the practitioner writes functions that accept and output data frames directly. I/O — in this case, persisting the data frame — is managed by a resource. Pipelines have modes, such as “test” and “prod”, that provide different resources at runtime. In this example, the “test” mode resource might persist the data frame to the file system, and the “prod” mode resource might persist the data frame to an object store such as s3, all while holding business logic constant.
- Flexible Execution: Dagster provides the ability to control execution from different environments — a laptop, a CI/CD pipeline, production, etc — while holding business logic constant.
- Clean, Intuitive API: Practitioners working in Python — e.g. data scientists using Spark or Pandas — can write and connect pure, vanilla Python functions to construct pipelines.
- Team Organization: Separation of concerns between business logic and I/O leads to a clear API layer between infrastructure and practitioner teams. Practitioners focus on business logic. Platform engineers provide APIs to abstract away I/O and infrastructure, enabling a fast end-to-end development workflow for practitioner teams.
Lightweight, schedule-less, ad hoc execution
Airflow Approach
Airflow DAGs couple a graph structure and a scheduling policy (e.g., run this at 3 am daily). This coupling means that DAG cannot run on two different schedules (e.g. a daily job and a weekly rollup). On a deeper level the DAG is not a standalone artifact independent of a schedule.
In terms of infrastructure, Airflow requires a long-running scheduler process to register and iterate on DAGs locally, making the experience laggy and sub-optimal. Local development is not normative, and when done, requires heavyweight infrastructure.
It is also a riskier proposition than it needs to be. The scheduler process runs continuously and frequently queries the database. It is easy to accidentally run scheduled DAGs and even kick off massive backfill jobs.
The concrete consequence of these conceptual and infrastructure issues is the absence of a clean, lightweight Python API to execute DAGs or subsets of DAGs without a running scheduler process.
Dagster Approach
Dagster is flexible enough to run computations without infrastructure requirements. No infrastructure, scheduler process, or stateful registration step is required to load pipelines or execute them.
Graph structure and schedules are also decoupled concepts; schedules and sensors are defined independently from a pipeline.
Advantages:
- Fast Spin-up: Dagster has an extremely fast and easy spin-up process. Define a pipeline with a few lines of vanilla code and then load it into a graphical environment for inspection and execution, or invoke it with a Python API
- Lightweight Python Execution APIs: Dagster pipelines can execute completely in-memory, with no required database or scheduler process.
- Lightweight Graphical Development Environment: Dagit, our web tool, requires no infrastructure, and can be used as a local development environment, like an IDE for DAGs.
- Multiple Schedules: Users can run the same pipeline or pipeline subsets on multiple schedules.
- Pipelines as Documentation: No infrastructure requirements and a web UI designed for local development make pipelines metadata-rich artifacts of documentation. As a practitioner, it is empowering to know that you can
git clonea repository, and instantly view those pipelines in a rich UI.
Because of these design decisions, we consistently hear the following from users who have transitioned Airflow to Dagster: Developing and testing Airflow DAGs is difficult, slow, or sometimes impossible. By contrast, development and testing in Dagster are not just possible, but fun and fast. Practitioners are happier, and the systems they produce are more reliable, robust, and amenable to change.
Deploy and Execute
Our belief: The orchestrator should be a rock-solid, multi-tenant platform, empowering teams with an independent, reliable deployment cycle.
What we hear from Airflow Users:
- “Anyone can bring down the orchestrator.”
- “Centralized task scheduler continues to cause scaling issues.”
- “I cannot independently and reliably deploy my DAGs.”
A core responsibility of an orchestrator is the ability to deploy code, schedule computations, and then reliably execute them in order. Because all data must come from somewhere and go somewhere, any practitioner or team that puts a data product into production must interface with an orchestrator. It inevitably becomes a multi-tenant, multi-tool platform, and must scale technically and organizationally.
Teams should be able to operate and deploy to an orchestrator independently. One team’s environmental requirements should not impact another team, nor should a team be able to bring down the orchestration platform with an errant push. A platform team should be able to centrally and reliably manage infrastructure on behalf of stakeholder teams.
Process isolation
Airflow Approach
Airflow’s architecture includes many components, including:
- A centralized scheduler responsible for scheduling runs and tasks
- A web server
- A set of workers for task processing
Schedulers and workers load and process all the DAGs at a frequent interval (the default is one minute). All user-defined DAGs and all Airflow components coexist in the same Python process. This has a number of disadvantages:
- Dependency Hell: All Airflow dependencies (nearly 100 packages on a clean install) and all DAG dependencies must co-exist in the same Python environment. Different teams may want to use different packages, versions of packages, or Python versions which is impossible with typical Airflow usage. This also complicates the process of upgrading Airflow and Airflow operators.
- Fragility: An errant check-in by a single team that fails DAG construction in production can bring down the entire platform. Similarly, a DAG construction performance regression reduces the performance of task scheduling across all tasks and teams.
- Monolithic Deployment: All teams in an Airflow instance must deploy monolithically. This also introduces reliability issues, as Airflow processes might evaluate these files during a non-atomic update (e.g., a git operation or an rsync command). Advanced users are often forced to pause scheduler processes, update code, and then resume scheduling. The pause-deploy-unpause cycle is a hassle to implement and complicates deployment processes.
Teams must pick between managing (1) a single, fragile, difficult-to-scale Airflow instance (2) managing many Airflow instances or (3) specifically structuring all DAGs to go out-of-process for team-specific business logic and infrastructure.
One pattern for moving all user-defined computation out-of-process is described in this fantastic article which advocates using Kubernetes operators exclusively. There are clear downsides and tradeoffs to this type of approach. It opts out of the ecosystem of built-in operators and integrations, which is a substantial part of the Airflow value proposition. It also, in effect, exchanges operational stability for an even more challenging local development environment, as it introduces a hard dependency on Kubernetes.
Another option is using multiple instances. A data platform team could centrally manage them or delegate the operational burden to stakeholder teams. Either approach incurs substantial centralized or distributed operational burden, respectively. It also means a regression into unencoded dependencies between teams, which was a major reason for adding an orchestrator in the first place.
Dagster Approach
In Dagster, system processes and user processes are clearly separated. Our system processes-the web server, the daemon-do not load user-written code into memory. Pipelines, resources, and other definitions are grouped together in a repository and accessed over an API.
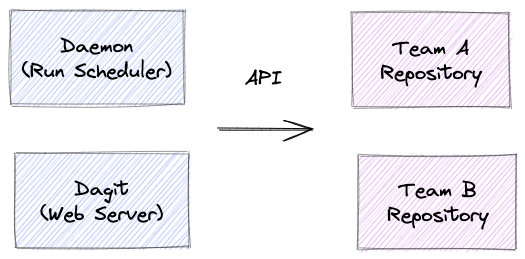
Advantages
- Isolated Dependencies: Different teams (e.g, data science, data engineering) often use different versions of python packages. Isolated dependencies avoid technical issues such as inflated docker image sizes, irreconcilable conflicts, and version mismatches. Teams can even use different python versions! This also isolates user dependencies from Dagster system component dependencies.
- Robustness: Process isolation means a more robust system. If a team pushes a failure that fails or slows down pipeline construction, system-wide operations are not impacted.
- Independent, Atomic Deployment: Dagster has out-of-the-box atomic deployment. When users update code, they update the repository without restarting system processes. Atomic deployment is more robust than continuously reloading code.
Flexible, Distributed Task Scheduling
Airflow Approach
Airflow executors — the component responsible for task execution policy — are instance-wide, limiting their flexibility. They must continuously load all tasks from all DAGs in process. More DAGs, tasks, and runs mean more workers, each of whom has to process more things. This an ever-present scalability bottleneck and point of failure. There is also no option to isolate execution at the run-level.
Dagster Approach
Dagster’s long running process, the daemon, is responsible for scheduling runs, not tasks. This allows for a layered approach, where Dagster runs are typically managed in ephemeral, single-purpose computational resources (e.g. processes, Kubernetes Jobs) responsible for task scheduling. Those in turn can decide on their own task scheduling policy.
Flexibly task scheduling allows for deployments tailored to user needs. For example, many users have found that with that run-level parallelism is sufficient without the need to parallelize tasks within that run. Without that flexibility they would have had to manage more burdensome centralized infrastructure.
Advantages:
- Flexibility: Users have many degrees of freedom for configuring allocation of computational resources.
- Horizontal Scalability: Each run-specific computational process executes independently. Runs horizontally scale.
- Cloud-Native: Ephemeral computational resources take advantage of fully elastic compute in public clouds.
Flexible, Event-Based Run Scheduling
Airflow Approach
Airflow models sensors (e.g., run every time this s3 bucket is updated) separately from time-based schedules (e.g., run daily at 4 AM.)
A sensor in Airflow is a task that polls, and might run forever. But it exists within a DAG that requires a time-based schedule (e.g. daily). Modeling the update frequency of the state the sensor depends on with cadence of the enclosing DAG is awkward. E.g., what happens when a daily run waits for an s3 bucket that updates twice per day on occasion?
Reported execution times are also counterintuitive, because they are just waiting for an event to occur, not performing data computations.
Airflow sensors also occupy a “slot” in the worker pool. When too many sensors are running, sensors can fill all task slots and prevent progress across all runs. Airflow 2.0 has introduced an experimental mitigating feature — smart sensors — to consolidate sensors in another process. However, this requires spinning up a dedicated, specialized process that adds operational overhead.
Dagster Approach
Dagster includes a daemon responsible for run scheduling. It decides — based on user-defined schedules and sensors — when runs start, launch, and distributes all other processing. The daemon unifies treatment of time- and event-based schedules (sensors) and its narrow remit results in a lightweight, operationally stable process.
The daemon invokes user-defined schedules and sensors in an external process, and computes the runs that should exist. It compares the desired runs with existing runs and computes what runs to launch. This reconciliation-based approach is naturally fault-tolerant.
Advantages:
- Narrow Scope: Managing run scheduling only makes this a lightweight, operationally stable process.
- Flexibility: Dagster schedules are customizable beyond cron expressions. Users can exclude country-specific holidays, for example.
- Fault-Tolerant: A reconciliation-based model makes it straightforward for users to write fault-tolerant schedules and sensors. The daemon also invokes all user-defined code out-of-process, so users cannot bring down the daemon process.
- Unification of Time- and Event-based Schedules: Sensors are peers to schedules in Dagster, rather than infinitely running tasks within a time-based schedule as in Airflow.
Monitor and Observe
Our belief: The orchestrator should be a consumer-grade, data-aware monitoring tool for fast debugging and self-service operations by a broad spectrum of users.
What we hear from Airflow Users:
- “I don’t know what computations inside my DAGs do.”
- “DAGs are difficult to debug quickly.”
- “I have no idea where my data comes from.”
- “The UI is showing its age.”
Once deployed, platform operators must monitor computations and observe data. External systems that computations depend on will fail. Incoming data will change in ways that cannot be anticipated. In other words, failures are inevitable.
The orchestrator is the natural center of gravity for monitoring and acting upon all these unavoidable errors. It invokes every tool, and those tools produce every data asset in the enterprise. Practitioners spend a lot of time within this tool.
Users deserve beautiful, well-designed tooling that allows them to navigate to errors, inspect runs, and find produced assets with ease. Using the tool should be fun.
Structured Event Log and System of Record
Airflow Approach
Airflow, by design, knows little about what user code is doing at runtime. This lack of information means a lack of support in tooling for debugging and observing computations within tasks. The primary support it provides is a searchable per-task, raw-text log. Navigating the UI is cumbersome and we frequently hear that combing through these unstructured logs to find pertinent information is a burden.
The absence of an structural, immutable record of activities has other impacts as well. Airflow’s history cannot be fully trusted as many operational tasks destroy history. For example, retrying a run for a particular date requires deleting the previous run associated with that date. It also does not preserve historical DAG structures so runs are not reproducible.
Dagster Approach
The core of Dagster’s monitoring and observation capabilities is its structured event log. It serves as an immutable record for computations in Dagster. The log drives Dagit’s reactive UIs, builds our asset catalog, and powers UI affordances such as well-formatted stack traces and markdown rendering directly within the run viewer.
Every executed pipeline and every event created is recorded in this immutable log, allowing it to serve as a system record for your data platform.
Advantages:
- Fast Navigation: The structured event log allows for fast navigation to important entries, like error messages. Users can find them in a few keystrokes and display well-formatted stack traces.
- Rich Metadata: Users can embed arbitrary structured metadata in the event log. They can track properties over time. They can have rich display options, like a markdown viewer, to display samples of data within the tool in production.
- Reactive UIs: Our events are an immutable log stream, which lends itself to live, updating UIs.
- Reproducible History: Any historical run or graph structure can be reproduced, no matter what has changed in the system.
Asset- and Dataflow-Aware
Airflow Approach
Airflow is unaware of the assets produced by its DAGs. Adding an external system to index assets requires an additional system to integrate and lots of code to execute the integration. Even then, there are limits to their integration with the orchestrator.
Dagster Approach
The Dagster structured event log includes information about the control flow of computations — successes, failures, retries, and so forth — but also what the computations are doing — what assets they produce and the data quality tests they pass.
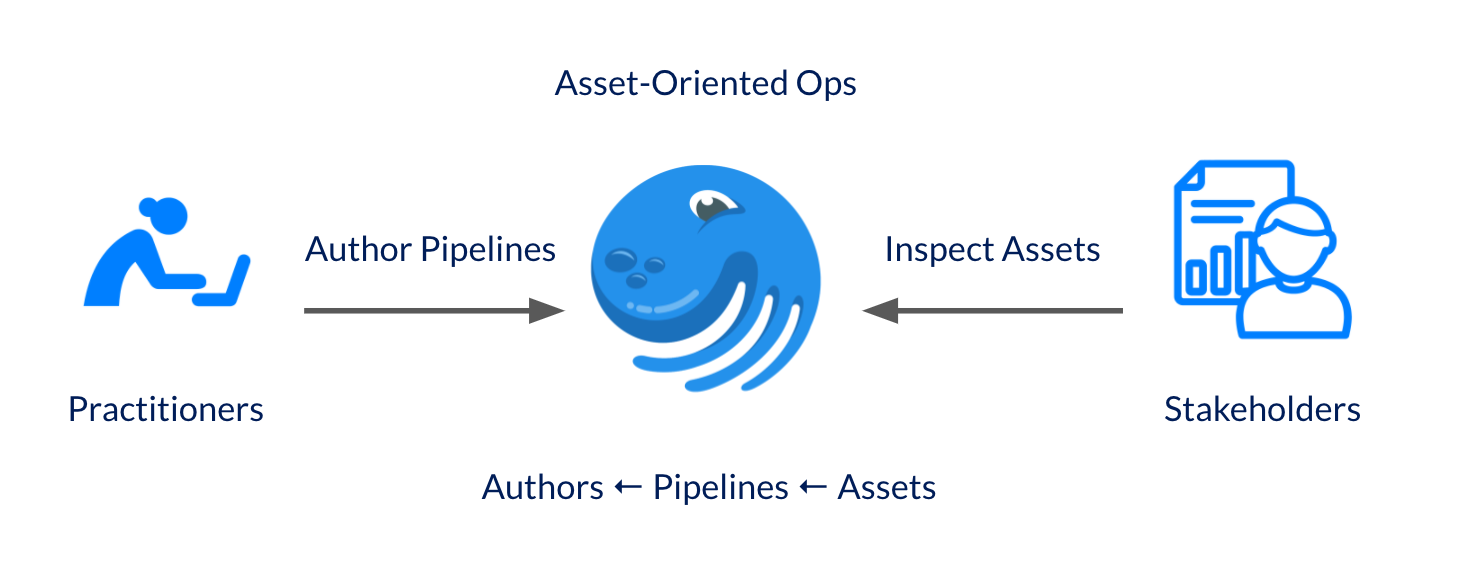
Dagster believes that the orchestrator should be asset-aware. After all, producing data assets is why these systems exist.
This information is used to build the Dagster Asset Catalog, a fundamentally new view into the operations of an orchestrator that links assets to the computations that produce them. Users can navigate into the orchestrator by searching for produced assets, rather than the pipelines that created them.
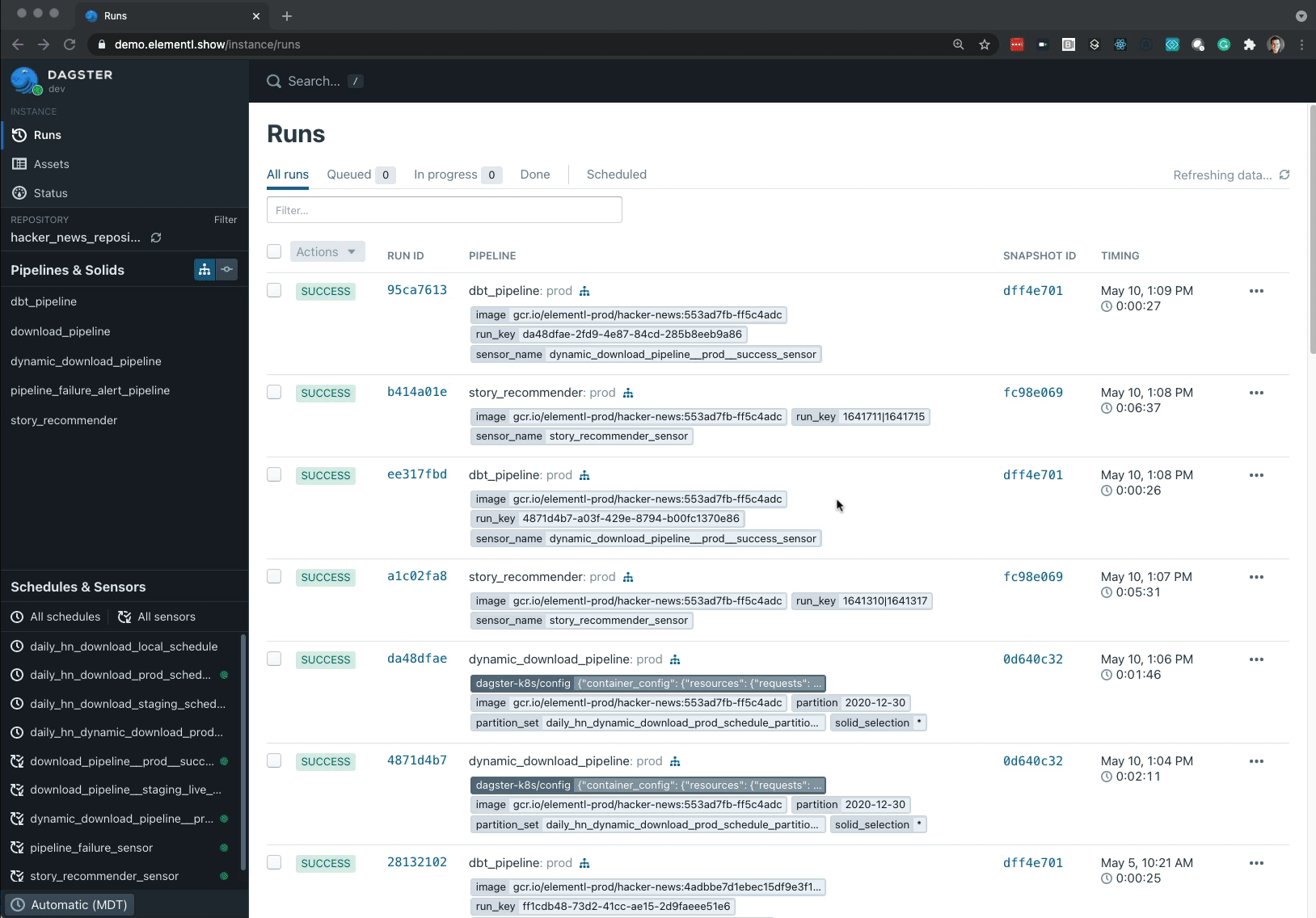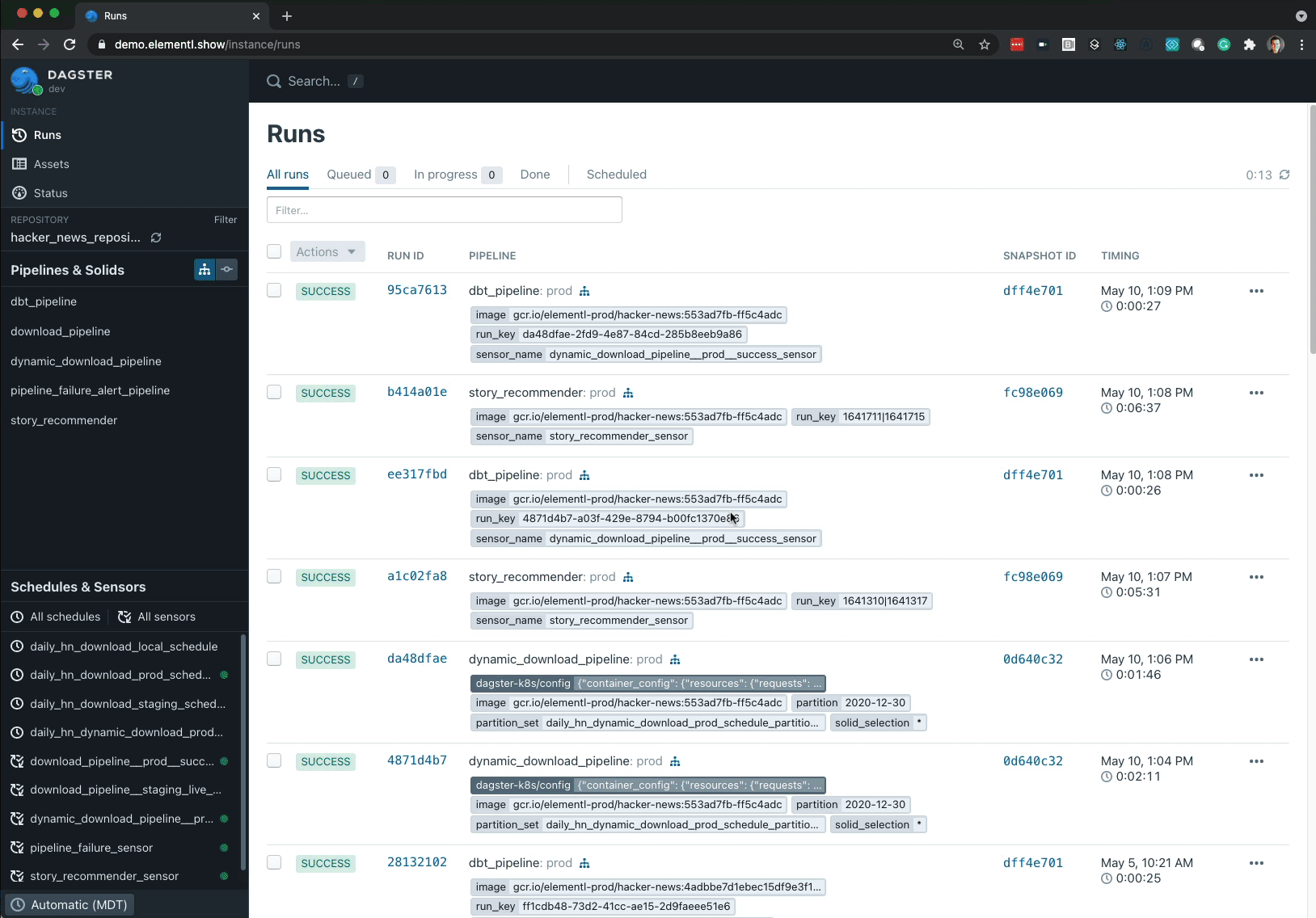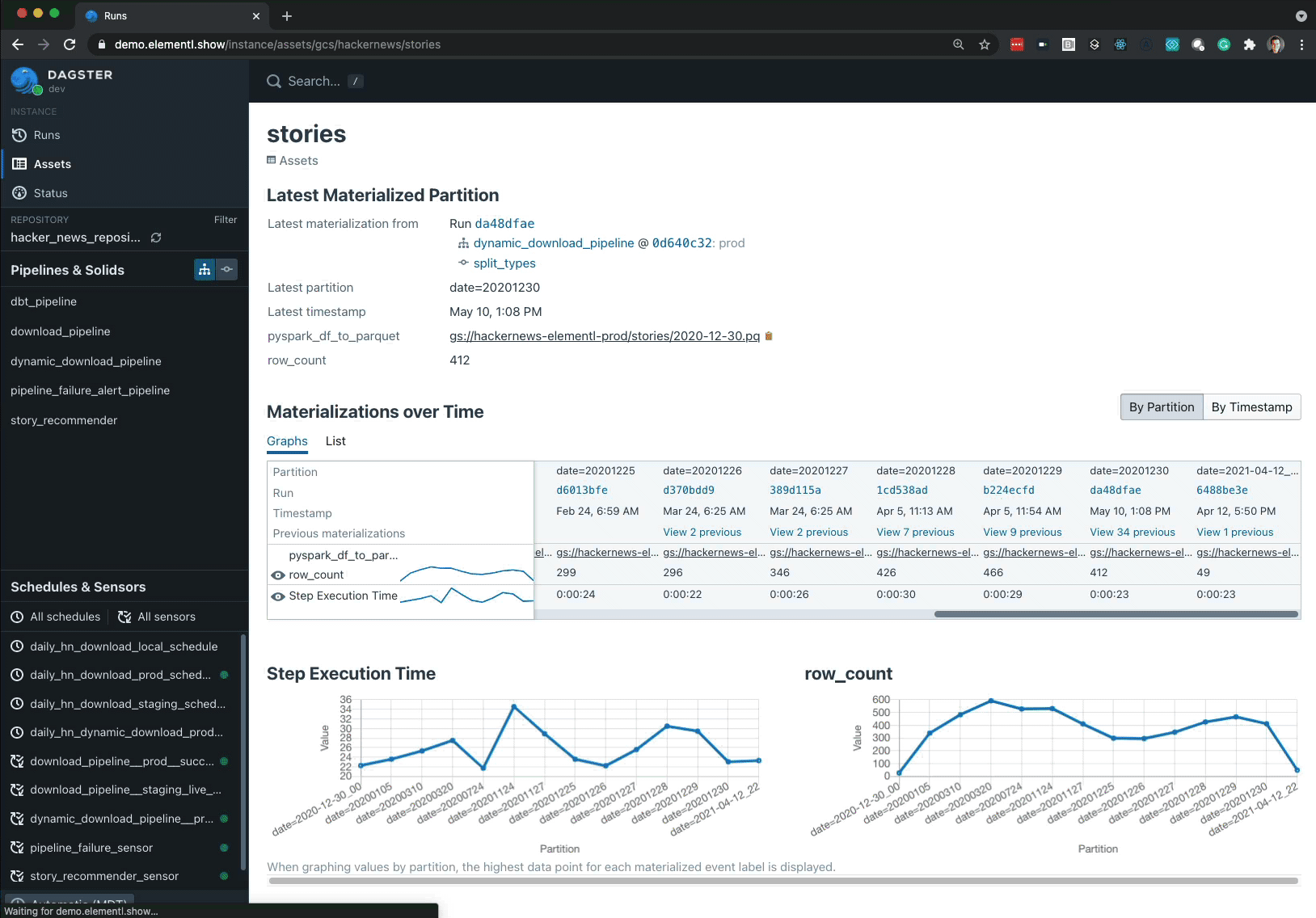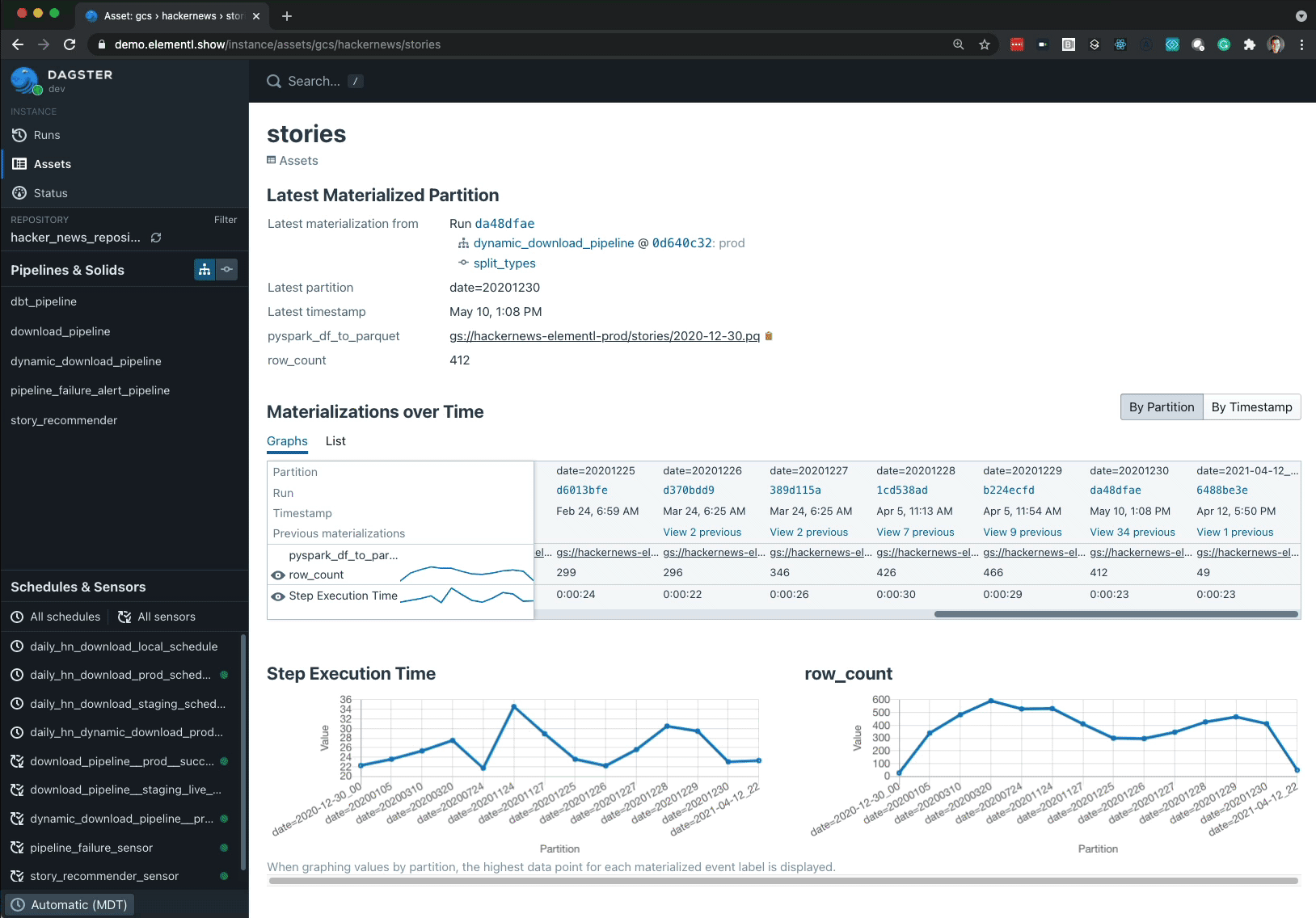
This is a profound shift because it reflects a deep, existing user mindset: Stakeholders don’t care about your pipelines. They only care about their data assets.
Without asset orientation, if a user finds a table (or other asset) that is out-of-date, or appears incorrect, it is difficult to trace what produced that table and whom to contact. Too often, the resolution is to scramble and contact the centralized platform team or to broadcast into a shared Slack channel. Instead the user directly navigates to that asset and can take action from there.
Advantages:
- Asset-oriented Navigation: Stakeholders can index into the orchestrator by asset name for operational workflows. They do not have to know the name of a pipeline to get relevant information. Pipeline names and structures become implementation details, as they ought to be.
- Longitudinal Views: Users can track and view the properties — e.g. number of rows, time it took to generate it — of a particular asset over time.
- Integrated Asset Lineage: The Asset Catalog supports asset lineage. Given that Dagster is aware of both data dependencies and assets, it is little additional work to construct an asset lineage graph.
- Assets as the Interface Between Teams: We believe that the interface between teams should be data products, not pipelines. Formally modeling sensors and assets provides a powerful tool for interconnecting teams: asset-based sensors.
Dagster does not seek to replace all data cataloging tools. We view our asset catalog as an operational catalog that takes advantage of vertical integration with the orchestrator. Our vision is to make the catalog the source of truth on the relationships between assets and the computations that produce them, a “single pane of glass” for operational workflows, and link out to data catalog tools for more advanced capabilities.
Conclusion
Dagster can serve as an alternative or replacement for Airflow (and other traditional workflow engines) as it performs the core function of scheduling, properly ordering, and monitoring computations. But it goes beyond the traditional definition of an orchestrator, reimagining the entire end-to-end process of building and running data applications. We view Dagster as a:
- A productivity environment for building and testing data applications in Python.
- A system that grows with you, from running “single-player” on your laptop to running an enterprise-grade, multi-tenant data platform.
- An observability tool that provides consumer-grade tools supporting self-service operations, fast debugging, and asset tracking.
With these properties, we believe the Dagster constitutes a huge leap forward in the orchestration domain which provides enormous dividends for data practitioners and platforms that adopt it.
Thank you for reading! To learn more come visit our GitHub repository, read our docs, and join our friendly Slack community.
Originally published at https://dagster.io.
Source: medium